Interesting ideas interspersed with nonsense - by nikhil bhatla
http://nikhil.superfacts.org/
Things I'm thinking about.2020-08-27T09:21:55-08:00My experience of a temporary scotoma (blind spot)
http://nikhil.superfacts.org/archives/2020/08/my_experience_o.html
Last December I had a once-in-a-lifetime experience. It was quite serendipitous too, because I have been thinking about this medical condition and researching it for the past 5 years... So here goes.
Before I jump in and say what happened to me, I want to give a bit of background. It has been known for at least 150 years if not longer that damage to primary visual cortex in the brain (abbreviated "V1") can cause blindness. Now, this is different from your run-of-the-mill blindness, which is usually caused by some damage to the eye itself, such as macular degeneration, glaucoma or cataracts. After cortical damage the patient's eyes are more-or-less OK, but it's where the eyes connect to, visual cortex in the brain, which has been damaged. So the singer is still singing, but no one is hearing her. Hence, blindness.
Now, there is a map of the retina (the light-sensing tissue in the eye) in the visual cortex. What is interesting is if you have damage to just part of the visual cortex instead of all of visual cortex, you will only lose vision in part of your visual field (i.e. what you see around you). For example, if you have a gunshot wound or stroke to left visual cortex (on the left back side of your head), you will lose vision only to the right of where you look, not across your entire visual field. This is because the parts of the retina that receive light from the right visual field send their signals to the left visual cortex (by way of the thalamus).
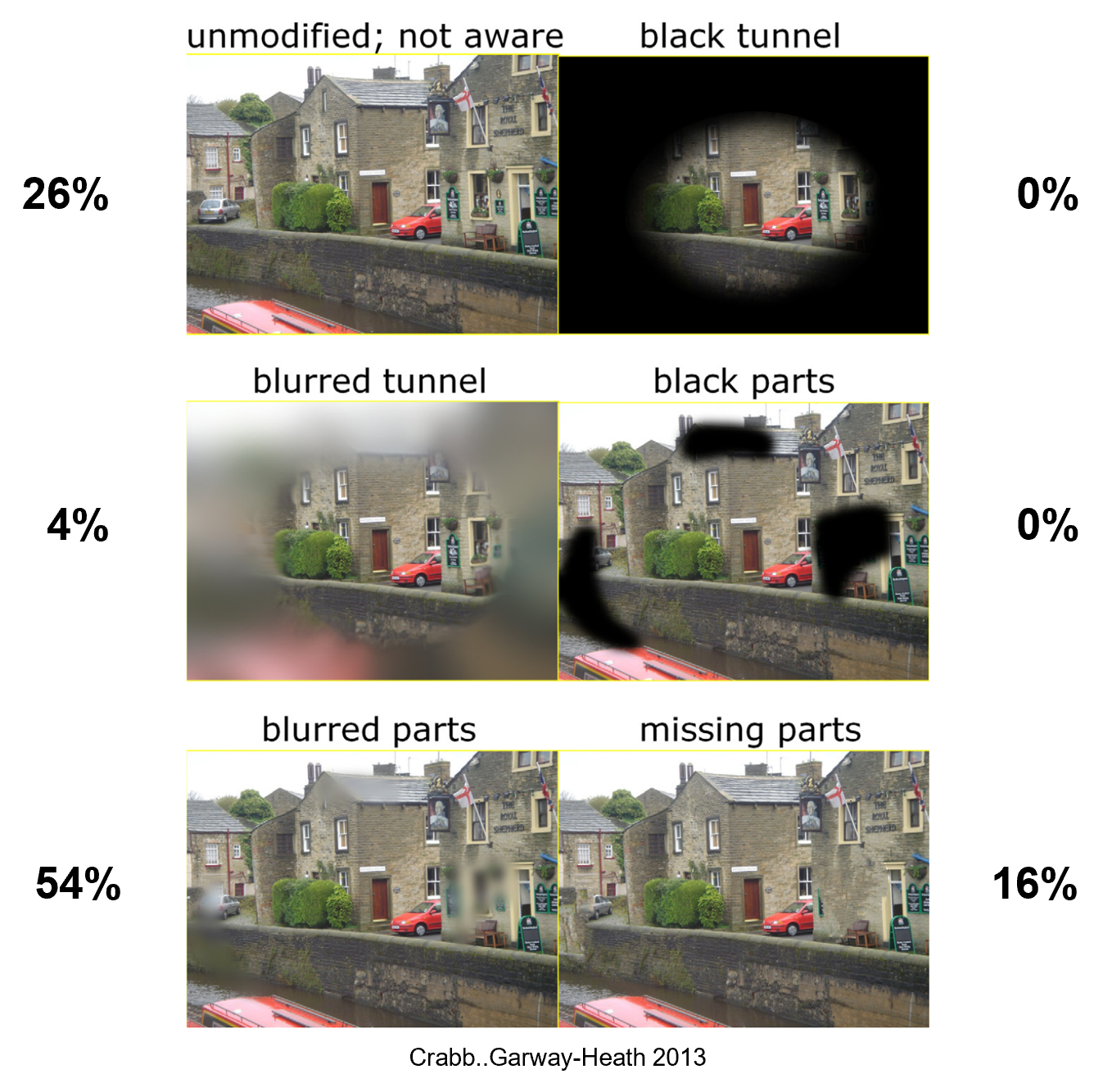
Now, there is a bit of a question as to what you actually see in that blind area, called a "scotoma" or "hemianopia", to your right. Does it go black, so you see a big black hole? Does it appear fuzzy, like bad eyesight? Or do you not even see it at all? One way to think about answering this question is to think about our eye's natural blind spot, which every person normally has. If you close one eye and move your thumb around at arms length in front of the open eye, you can actually see the tip of your thumb, including your thumbnail, disappear! Does the same thing happen to a scotoma caused by brain damage?
In one study (pictured below), researchers asked people with scotomas what part of the visual field with the scotoma looked like to them by showing several different possible images to their good visual field and having the patients pick one. Interestingly, no one reported seeing big black holes. Instead, most reported that the areas with damage looked blurry, and if not blurry then that parts were missing or that they couldn't even notice anything as wrong. The latter two experiences are exactly what happens in our natural blind spots.
Fraction of patients with scotomas reporting on what the scotoma looks like
That's the end of the background - now to my personal experience.
Last December around Christmas, I went to replace the batteries in my son's aquarium nightlight (a gift from Kostas and Angeliki). After putting the batteries in, unexpectedly it turned on and projected a very bright light into my eyes so that I was temporarily blinded as my eyes adapted to the light. I didn't think anything of it at the time except that it was mildly uncomfortable. After giving the nightlight to Becca I went back to my room to read an instruction manual (see pic below). Amazingly, I could not read. I could see everything fine to the left of where I was trying to read, but I couldn't see any letters to the right. So I couldn't read. Now, I didn't lose my whole right field, because I could still see things to the far right of my visual field. If I moved my eyes, the scotoma remained in the same relative-to-my-center-of-gaze position.
Normal vision, with gaze centered on center of pic
This is how the same scene looked with my scotoma. With my gaze in the center, I could no longer see any letters to the right so I could not read. Instead, the edge of the table and beyond came into the field of view where the letters should have been. It was as if the field was stitched across my scotoma.
If I rememeber right, when I closed either eye, the problem persisted, suggesting that this was a problem with my visual cortex rather than a problem with one eye itself. I do feel like the triggering bright light was seen in the right portion of my visual field, so somehow that bright light triggered a persistent blindness! I was a bit scared, but I decided to observe the effect more, as scotomas are part of what I have been researching at UCSF and UC Berkeley for the past 3 years using mice. So why not take this stroke of luck and learn from it, was what I was thinking.
I put my fist at arm's length to try to map the extent of my scotoma along the horizon. I could see my hand when it was close the the center of my gaze, but the moment it went into the right field it disappeared, until it reappeared again at about 30 degrees away from the center of my vision. I didn't map the scotoma's height extensively, but my impression was that it was equally large in height.
One oddity was that when I closed my eyes, I could see some sort of sparkling or rainbow Moire effect where my scotoma was. The colors were most visible along the edges of the scotoma and less so along its central portion (see pic below). I was surprised by the fact that I could clearly see the borders of the scotoma when I closed my eyes, yet when I opened them I had to do the hand test to define the scotoma's location. I wonder if people with permanent brain damage also see the scotoma border with their eyes closed. Also interesting was that with my eyes closed I could see the scotoma growing in size, until it nearly doubled or quadrupled in area. When I opened my eyes and did the hand test, the scotoma now encompassed from my central gaze to 45-60 degrees to my right. It then stopped growing and persisted for some minutes, during which I went to sit in a dimly lit room. I drank some water and started getting a slight headache and feeling nauseous, all signs of a migraine. I had never had a migraine before in my entire life.
Dark oval is my field of view with eyes closed. You can see the scintillating colors around the perimeter of the scotoma. The center was more black and white snow noise, just slightly higher contrast than my full field of darkness. I often seen this visual noise when I am drunk. Note that the scotoma was not actually perfectly circular as drawn here, but irregularly shaped.
After about 30 minutes the scotoma went away and the slight headache and nausea started. Then after about an hour those feelings also subsided, and I was as good as new.
So that was very interesting. If it happens again (could I induce it again with a bright light?), I will test myself for blindsight with Becca's help. ]]>Comments: ]]>Poonam: Very interesting. When you explained your new experiment to me you didn't share your personal experience. I am not surprised. It is a very keen observation on your part and a fascinating study of the visual cortex if you pursue it further.
It also reminded me of the old camaras that would blind you for a bit with their flash...although,I did not pay attention to what I saw after I was blinded and for how long.
Anyway sounds like a good experiment but please don't try it in yourself again...you have your mice for that.
Good luck!
Bharti: Very interesting. This explains the feeling that at times I was oblivious to my surroundings. Good luck with your research and would be very interested in your findings
Ed: Great to see this blog still kicking! I've been coming here for the past decade (mostly for the wormweb.org).
Elon : Interesting blog mate, please consider to apply for neuralink , just checked your amazing track record on linkedin.
Kat: I have visual field lossloss. Yep totally just unaware I'm missing vision now infact I forget even seeing a driver next to tyou, in the car was normal 4 yrs ago! Mine is permanent I have a refractory error. When faced with light stare at sun close eyes I only get the orange dots in remaining vision areas never lost one's. Note cerebral hemmorage and infarct py.
Cardinal: I've also experienced this once a couple years ago, A small region of my eyesight just kind of disabled itself and I see how my brain was filling in the gaps, using the surrounding vision to assume what should be there. It lasted around 30 minutes and then faded away.
Someone: This is migraine aura ]]>
Write Comment]]>
Consciousnessnikhil2020-08-27T09:21:55-08:00A Follow-up on X, after 12 years
http://nikhil.superfacts.org/archives/2019/12/a_followup_on_x.html
Man, it has been almost 3 years since my last blog post. Having a kid sure does make time scarce in a way I had never experienced.
I found myself writing a long email response to a stranger on an important topic, so I figured that could be a blog post.
He wrote: I came across you while considering the BOSS survival camp. And in doing so, I came across your old blog and was very intrigued by your experience at BOSS and your quest for "X" after the fact. I see you have sponsored some students in the past for BOSS and even done your own experiments to re-capture "X". I am curious to know your findings and if it was possible to re-capture for an extended period of time. With "X" being so amazing and creating a euphoria, is knowing what it is like and now not being able to obtain it a bad thing (making things now mundane)? Or still worth it knowing what it is like/what is possible?
I have been considering the 28-day BOSS class for the past 3 years, but have not fully committed yet due to financial and time-constraints. I'm not only interested in the survival skills learned, but also to become more self-aware and appreciative of life and daily occurrences. This "X" is very intriguing to me.
Thank you for your time and I hope me reaching out isn't an inconvenience.
So here is my response:
Thanks for the email. Yeah, X was never something I expected to experience post-BOSS, and it was the most significant effect of BOSS. It is difficult to describe to others who have not experienced it, and even if you understand it on a cognitive level you don't really understand it until you understand it at the experiential level (which I guess is true of most important things in life). X is also an ambiguous term, as I've talked with several friends post-survival school about X, and for a moment I think we are talking about the same thing, and then after more discussion I learn that maybe we aren't - or maybe we are. The phenomenon/experience itself requires further defining and articulation, but I've done what I can with the blog post. Here is a little more:
Post-BOSS, after returning to civilization, I had an experience of X that lasted from August to October, or about 1-2 months. X is multi-faceted and it at least involved the absence of all anxiety (which I had never experienced before) and a sensitization to the everyday pleasures of life: Love (seeing people hold hands made me feel warm - I had never experienced that before); Food (every flavor was a novel, savored experience, and my stomach had shrunk, so both features together meant I ate everything slowly; as an example, over 1 day of a road trip I ate just 1 cookie my girlfriend had baked; also, food was so amazing that I didn't want to talk to anyone while I was eating, as talking distracted from the experience in front of me - now, I can barely eat without having a conversation in parallel); and the Basic Comforts of shelter, a bed, a shower, and not having to walk everywhere (driving truly is marvelous).
Note that X happened when I came back; it was not present during survival school. During survival school I was mostly in a state of deprivation - hungry, cold, wet.
When X was gone, I wondered 1) if it could be recreated outside of survival school, and 2) if it was a 1-time thing or could be experienced over-and-over. I never went back to survival school, so I don't yet know if it was a 1-time thing. But I tried a couple experiments to see if I could recreate it outside survival school. In the first experiment, while in grad school, over 28 days, I ate the same diet as in survival school and walked 6 miles a day (to simulate the hiking done in survival school) to and from the lab. I lost the same weight I had lost in survival school (about 20 pounds, dropping from 160 lb to 140 lb), but I barely had any X after I was finished. So that was a big disappointment. In the second experiment, my friend who had also done BOSS and I went on a 7-day BOSS-style trip to Yosemite. We took the same limited supplies and rations. My friend was smoking a lot and in very bad shape, and it was so easy to quit, so we only lasted 2 nights before we bailed. Suffice it to say that we again did not experience X.
The real test for me is to go back on another 28-day trip. I have a son now so this is much more difficult, so it probably won't happen for another 15 years or so. Perhaps sooner. But my need to go back has also waned. I think part of the reason might be some of the long-term effects of BOSS and other changes in my life since BOSS (which was now 12 years ago).
Knowing what X is like and not being able to attain it again has not been a bad thing for me. Just knowing it exists perks me up. But this will likely depend on your personality. My friend who did BOSS (and who I went to Yosemite with) got very depressed after X went away. So I can't tell how one might respond to its loss. My friend has said that being at Burning Man has elements of X in it - I have not been yet but am very interested to go one day to see this for myself. This might also be a clue as to why I was not able to recreate X in my experiments, and I have more to say about this, perhaps at another time. ]]>Comments: ]]>cptobv: i experienced x with lsd. no anxiety, food was better, etc
nikhil: cptobv,
Does X occur every time you take LSD? How long does X last - only while you are on LSD, or after?
Kirk Carlson : Definitely are not missing anything. Nothing today seems close to what they were in the past. In fact for the little bit of euphoria you get you have so much more in consequences. It makes sense that as we advance in science that the people making things would get better at making sure you want more. It's like it's purposely designed to do very little other than make sure you want more and before long there is no stopping. Fortunately thanks to boss training when I came across it I could tell something was wrong and kept my distance. ]]>
Write Comment]]>
Lifenikhil2019-12-01T22:19:01-08:00The way
http://nikhil.superfacts.org/archives/2017/03/the_way.html
I think
about what it would be like
to not think
the way that I think.
Not thinking about thinking
To just think, straight up.
A trap laid beyond my feet.
Is the sadness of the loss
of the second parent
easier to bear
because of
the loss of the first?
Does sadness vaccinate
against future sadness?
Do darts that pierce through
yield
to darts that barely prick? ]]>Comments: ]]>Tim: Ended up here somehow from looking at a chemotaxis simulation you made - because I wanted to make my own and was disappointed that one exactly like I wanted already existed. Didn't know what I expected to see when I got here, but as someone who has been really sad about their parents declining health, it strange to know someone else has wondered in much the same way I did. So thank you for both the science and the introspection. Gotta get back to lab work now.
Kirk : Thinking can be a bit overwhelming. I find that when I'm lacking in something I'm thinking of how fixing. I think it is important that as I go on I remember to stress less and try to not put myself in positions to need to stress.ive recently experienced loss. As I'm healing I wonder if I'll ever be whole again. My parents are getting up there wonder how ill feel when they are gone. ]]>
Write Comment]]>
Poetrynikhil2017-03-24T23:47:24-08:00Sadness sparks
http://nikhil.superfacts.org/archives/2017/03/rain_fire.html
Sadness sparks
that energy everlasting
a welt of wounds
shallow, deep
compounding
manifesting
creation
that is life
making us be.
Sadness plunges
the soul down
to that home
of sensitivity
conceiving no ills
but them all.
To break through sadness
to mend the tears
that wet separation
only to be chucked back
treading
enclosed
inescapable.
Remembering finality
to resuscitate
that wet flame. ]]>
Write 1st Comment]]>
Poetrynikhil2017-03-24T23:12:40-08:00The End of LendingClub?
http://nikhil.superfacts.org/archives/2016/07/the_end_of_lend.html
There are 2 parts to this story. The first is about LendingClub's (LC's) actions as a company, and the second is about my returns on the site.
Early on in LC's history (2007-2009), they advertised a 9% return for investors, right on the front page of their website. I was always skeptical of this from the beginning, because I didn't believe that they properly factored in the default rates of the loans. There is a fundamental difficulty with estimating returns on loans (3 year duration for LC's first generation of loans): returns are high in the beginning when loans haven't had much time to default, and drop over time. So if you have a portfolio of very young loans, you will likely overestimate your return. LC's loan volume has been growing so rapidly that the site-wide portfolio has always been very young. After the first batch of loans were 3 years old and I had a chance to analyze only those loans that had had a chance to go to completion, I found that the return was half of what they had been advertising, closer to 4.8%.
Strike #1 - LendingClub advertises inaccurate estimates of investor ROI, due to underestimation of defaults.
Still, a 5% return was not bad, and that was site-wide. I had some filters setup based on lending experiences on Prosper and LC, so I thought I might be able to do a bit better, around 6-8%. That seemed worth the work of spending 15 minutes every morning reinvesting principal on the site, which I did for several years, until 2014. Payments come in as interest + principal, so to really get the maximum return you need to keep reinvesting the principal. Contrast this with bonds, which make interest payments (the coupon) and pay back the principal at the end of the term. Uninvested principal due to regular payments and early repayment of loans is a necessary headache to be dealt with these kinds of investments.
As an aside: LC never made a good automated investing feature on its website - in fact, the UI and feature set is essentially unchanged since 2009. That on its own is a bit pathetic for a so-called "tech" company, but I think it represents a kind of inertia and lack of connection with its individual investors.
In addition to the complication of prepaid principal, the second complication with LC is how taxes are computed. All interest is counted as ordinary income, and all defaulted loans are counted as capital losses. From a holistic point-of-view, this is a bit backwards, as I would have expected the losses to be deducted from my interest earnings, and the leftovers to be taxed as ordinary income. Alas, this isn't the case. Note this isn't specific to LendingClub, but is an issue with a lot of loan-like investments, including bonds. What is specific to LendingClub is their whopping-high defaults, which have ended up being 40% of my interest earnings. If you are able to sell capital gains to recover the capital loss benefit, your effective tax rate is increased from 30% (fed + state) to 37% on this LC income. This caused my post-tax ROI to drop by 33%, from 6% to 4%! I'll give some more detailed numbers later, but this sucks.
The main issue here is that you can't compare LC ROI to another income investment's ROI, like a bond fund, because the tax consequences are so different. So LC looks great at first, than surreptitiously bites you when you go to pay taxes.
LC never clearly explains this tax situation when it is advertising its ROI, and the investor doesn't realize this until they start doing their taxes. I didn't full quantify the magnitude of the effect until after many years of investing, and many investors I suspect may not even notice.
Strike #2 - LendingClub again inaccurately estimates investor ROI, due to the tax consequence of high rates of default.
OK, 2 strikes. Still, I can manage the tax consequence and factor that in, and factor in more reasonable default rates. Perhaps I can still make a 6-8% return? Ahh, but the work of lending every morning is starting to wear on me.
Voila, as if they heard my issues, they start their own LC fund (called BBFQ). This removes the burden of me picking the loans each day, and the tax consequences should be better, or so I was told (this later turned out not to be true - the tax consequences ended up being just slightly worse). The downside is I don't get to use my special filters anymore, but the fund had averaged 8% or so over the past couple years, so maybe I don't need my special filters. Also, the fund invested in 5-yr loans in addition to 3-yr. I only ever invested in 3-yr loans. But 2/3 of the fund is supposed to be in 3-yr and only 1/3 in 5-yr. Maybe this is what I've been waiting for?
So I invest in the Fund at the end of 2014, pulling most of my money out of the website, and 2015 returns are alright (see below). Then, the founder and CEO is forced out in May of this year because he did not disclose an investment in an outside fund that LendingClub itself is considering investing in (conflict of interest), and because some loan applications were incorrectly dated to match an investor's criteria (fraud). WSJ has some good coverage, and I take a closer look at the Fund. Turns out, the Fund has not been investing to its target ratio of 66% 3-yr, 33% 5-yr loans. Instead, it has inverted, and has been investing 60% in 5-yr and 38% in 3-yr loans. I found this very suspicious, as 5 yr loans have higher interest rates, but greater risk, so it looks to me like LC is pumping up the returns in the Fund, just like they had inflated returns on the website. I call them to ask why this is happening, and they can't give me any definitive answers. Regardless of why, it is a violation of the stated portfolio strategy, so there is clearly a lack of internal control in the Fund.
Strike #3 - LendingClub is unable to maintain the portfolio targets they advertise for their Fund.
Then, on June 28, they send out an investor letter. June will be the first ever month of losses in the Fund, which I can handle. But they also report that additional investigations have found more acts of dishonesty in the company. First, the (now booted) founder borrowed money on the site in 2009, apparently to pump up their loan volume numbers for their VC investors. This sounds like a spoiled culture from the very beginning. Second, the Fund bought loans that no one else would buy on the site earlier this year, in violation of its stated investment strategy.
Strike #4 - The LendingClub Fund (and company) have a lack of internal control, which allows erratic and unethical behavior.
Now they have laid off 12% of their employees. There was 1 week when no new loans were listed on the site. Random stuff seems to be happening.
I expect more disclosures of ineptitude over the coming months as they audit all of their internal processes. But I suspect this might be a dishonest company at its heart. They may be able to change, but after 7 years of swallowing their issues, I think I've had enough.
Nonetheless, all of this risk would be worth it, if the returns were sufficiently high. Sadly, they are not.
Here are my pre-tax returns on LC's site (non-Fund), all on 3-yr loans:
2009: 7.1%
2010: 5.7%
2011: 5.3%
2012: 6.7%
2013: 6.5%
2014: 6.5%
2015: 4.1% (drop is because I stopped investing on the site and moved money into the Fund)
My pre-tax return on the Fund in 2015 was 5.7%, but my post-tax return is actually 3.6%. And 2016 is looking worse, with a pre-tax return of 3.2% and a post-tax return of 2.0%.
Altogether, over 7 years, my pre-tax annualized ROI on the LendingClub site was 6.1%, and over 1.5 years on the Fund was 5.1%. But my post-tax ROI on the site, properly accounting for capital losses, comes out at 3.9%.
All this work and nothing that amazing to show for it :( The post-tax return of 4% on a California long-term municipal bond fund is starting to look mighty appetizing. So much simpler, and without the tax headaches and company drama.
Of course, the bond fund has its own issues, esp. how bond yields will respond to upcoming interest rate increases, if in fact the Fed every decides to start those... ]]>Comments: ]]>chandl34: Another issue with capital losses is there is a limit you can claim per year. If you over-invest in LendingClub (or other similar platforms), you will always have more capital losses than the yearly limit. It seems the only way to claim those carry over losses is to de-invest completely from LendingClub.
Kirk : It's sad to watch It. Some companies have the ability to make a lot of money, and they just don't do it properly. It's a shame the truth is. What can you do about it? Unless you create your own company and then you your own 2 diligence. Really wish those numbers would have sounded better, though. ]]>
Write Comment]]>
Investingnikhil2016-07-14T12:05:47-08:00Can the Bitcoin be Money at a National Scale?
http://nikhil.superfacts.org/archives/2016/05/can_bitcoin_be.html
I was at a neuroscience conference (SFN), and instead of absorbing some of the fresh science compressed into the San Diego Convention Center, my mind was elsewhere. By the third day I had had enough, so I just started walking and ended up in Little Italy.
It was November 2013, and the media had declared Bitcoin a Category 2 tropical storm, on its way to becoming a Category 5 hurricane. Bitcoin's price was $370, and within the next month it would rise to more than 3-fold its value, peaking at $1150 in December.
I had read about Bitcoin about a year before, but only with this latest round of press did I become intrigued. Two questions stood front of mind. First, ctould bitcoins actually function as real money, a currency alongside the dollar and euro, as its champions proclaimed? And second, were bitcoins a good investment, especially if they might one day function as national money?
The key breakthrough of Bitcoin, and the linchpin feature in its quest to achieve money-vana, was that it was by implementation a scarce digital good. All of my interactions with digital objects so far went hand-in-hand with copying. Need to make significant changes to an essay? Just copy it and edit the copy. Need to watch a video online? Youtube just copies it to your computer and then you watch it. Sure, some copy restriction tech has been developed (DRM), but a motivated individual can work around these digital shackles, springing the underlying digits.
So a bitcoin was unlike all digital objects that came before. It was a digital object that was not copyable, and its scarcity was enforced by the software that gave it its very existence. Bitcoin account values are tracked using a special digital ledger called a blockchain, and this blockchain is maintained and updated by thousands of computers communicating with each other via the Internet. To transfer bitcoins between addresses (accounts), the transfer must be recorded in the blockchain. To be recorded in the blockchain, computers compete to complete a computationally expensive and unpredictable task, and the first to complete this task gets to record the bitcoin transfer on the blockchain and gets rewarded with fresh, virgin bitcoins. In this way, the system reinforces its very own existence, by incenting compute time with more of the scarce digital good. By being scarce, bitcoins have a shot at being digital money.
So bitcoins seem to resemble conventional money, its advocates claim it is money, but is it actually viable as money? More specifically, is it viable as money on a national scale? It is well-known that bitcoins are used as payment in illicit transactions (guns, drugs, etc.), so it is already used as money in certain circles. But does it have the potential to be money at the level of the dollar or euro, i.e. at a national scale?
To analyze Bitcoin's prospects, the first step is to define the two key terms, "bitcoin" and "money". Bitcoin is a now famous software system that generates and tracks scarce digital tokens, allowing transfers between accounts that people interpret as payments. So that's Bitcoin - but what exactly is "money"?
I have struggled with answering this question for the past 2 years. If you look up "money" in an economics textbook, it will tell you about the 3 functions of money:
(0) Medium of exchange: "Money serves as a medium of exchange in that it is an item that people are willing to accept as payment for what they are selling because they in turn can use it to pay for something else they want." (Taylor 1998)
(1) Store of value: "Money also serves as a store of value from one [time] period to another." (Taylor 1998) This feature means that you don't need to immediately use your money once you get it, as it won't go bad or degrade from just lying around. Money retains its value. This feature implies that the supply of money must remain relatively fixed and low (i.e. scarce), otherwise the value of each money token would drop, resulting in an increase in prices (i.e. inflation). Then the token would no longer be a good store of value.
(2) Unit of account: "Money also serves a third function, providing a unit of account. The prices of goods are usually stated in the units of money." It can be hard to grapple with how this is different than money's function as a medium of exchange, so here is an example: Sometimes when I travel outside the US to another country, goods are listed in the local currency, but the shop owner will happily take dollars as payment (after applying an exchange rate). This is an example of when the unit of account is in one money, while the medium of exchange is in a different money.
Despite the fact that economics portrays these 3 features as being on equal footing, it has become clear to me that a token's function as a generally accepted medium of exchange (#0) is the key feature that transforms a token into money. Exchange is the standard way that we use and think about money (e.g. "How much does this cost?"). Sure, a token of exchange is preferred if its value isn't lost over time (#1). It is also simpler to do transactions and pay back debts if the units of account match the units of exchange (#2). But features #1 (store of value) and #2 (unit of account) are important insofar as they support feature #0, money's primary function as a medium of exchange. If a token was either a store of value (e.g. real estate) or a unit of account (e.g. number of favors owed) without being a medium of exchange, I don't believe we would recognize these tokens (real estate and favor debt) as money. Money's defining characteristic is its function as a medium of exchange, as a generally accepted token used for payments.
The economics textbook cited earlier also makes the same point, though not as unambiguously:
[Money] is the part of a person's wealth that can be readily used for transactions, such as buying a lunch or selling a bicycle. Thus, money is anything that is generally accepted as payment for goods and services, not because it is inherently attractive or appealing, but because it can be used to pay for other goods and services. (Taylor 1998)
So, are these two subsidiary features (store of value and unit of account) sufficient to promote small-scale money to national-scale money? I think the following additional features are important for tokens to become money on a national scale:
(3) Divisible: The token should be as finely divisible as practically needed, to resolve the problem that occurs during uneven exchange. For example, if I give you a $20 bill for something priced at $1, there needs to be smaller denominations of dollars available that I can receive as change, otherwise the transaction will be less likely to occur, making the $20 bill less generally acceptable as a medium of exchange.
(4) Stable value: The token should not only retain value (feature #1), its value should be relatively stable. If the token's value increases too quickly, then owners may not want to give up their tokens in exchange for goods and services, instead opting to trade with a token who's value is not changing. Likewise, if the value of the token is decreasing, sellers may not want to take the depreciating token in exchange for their wares, expecting it to be worth even less later. So for people to use a token as a medium of exchange, its value should be relatively stable. A token with high price volatility is unlikely to succeed as money.
(5) Recourse: The owners of tokens should have recourse, either legally or through another social mechanism (e.g. insurance company, credit card company), that facilitates documentation and attempted recovery of stolen tokens. If your tokens are recovered, then they are returned to you. If they are not recovered, they are lost to you, though your claim of theft remains.
(6) Private: The token should support private exchange, in which the transaction's occurrence and amount, as well as the identities of the object sold and the participants, remain undisclosed to the public.
(7) Simple to use: While the infrastructure supporting a token as money may be extremely complicated and incomprehensible to the user of money (as is the case with any sovereign currency), the actual user of money should find it simple and convenient to use. For example, if I had to do 2-factor authentication whenever I spent a digital token, that increase in complexity relative to swiping a credit card would discourage my use of the token as money. Even today with the advent of chip readers for chip credit cards, the authentication process is so much slower than swiping that I expect that the transaction rate and transaction quantity have decreased significantly.
(8) Reliable: The token system should be resilient to temporary infrastructure failure. The US dollar system is resilient: if the digital system of credit and debit networks goes down, transactions can still be conducted with the physical system of dollar bills and coins. Such a bimodal token system functions more reliably as money than a unimodal system, whether solely digital or solely physical.
(9) Interoperable: The token should be exchangeable for a variety of other national moneys, which internationalizes the token, making it generally acceptable at an international scale by proxy. This supports foreign travel and international commerce.
(10) Advantageous: If the token is introduced into a community that already has a token used as money, the new token should provide substantial advantages to overcome the inertial advantage of the preexisting money. These advantages cannot be small and must be substantially greater than the cost of switching platforms.
One final point that is worth stating is that tokens to be used as money can be created either as a form of debt/liability (e.g. most money today is a liability of the banking system) or as an asset (e.g. gold, bitcoins). World governments have converged on debt-driven moneys, so there may be practical advantages to a money supply that supports debt creation as a monetary policy. This is a more complex topic that may be worth analyzing later. For now, it seems to me that tokens generated either as debts or assets can work as money.
Having established an extended set of criteria that more accurately reflects the modern, practical requirements of money, how does Bitcoin fare?
(1) Store of value: Good, but not in a way that supports its function as a medium of exchange. Unlike sovereign money that increases in supply over time due to inflationary monetary policy, bitcoins were designed to be available, after an initial inflationary period, in a fixed, constant amount of 21 million bitcoins. A fixed supply suggests that its value will not drop, so inflation is unlikely to occur. Instead, the value of a bitcoin is expected to increase and cause deflation, which is a potentially bad property of the bitcoin in the context of exchange. By increasing in value, owners will reduce spending of bitcoin, which handicaps its ability to serve as a medium of exchange. This might make it a good investment, but bad at functioning as money.
(2) Unit of account: Good. It is easy to price goods in bitcoins, since there is a ready market for trading bitcoins for dollars and other sovereign money.
(3) Divisible: Good. A single bitcoin is theoretically divisible into 1/100,000,000 parts, which is a much higher divisibility than sovereign money.
(4) Stable value: Poor. As alluded to at the beginning of this post, the bitcoin suffers from high price volatility. In the last year the price has increased from $236 to $445, an increase of nearly 90%! In the last 2 years, the price is down from $584, a drop of nearly 20%!
(5) Recourse: Poor, though possible in some cases. You can report loss of bitcoins to the government, and in some cases, if enough people are affected, the government may pursue an investigation and recovery process, as Japan did in the case of the abrupt dissolution of the Mt. Gox exchange. In general, however, there isn't an authority or security service within the Bitcoin infrastructure that tracks and returns stolen bitcoins. Unlike credit cards and like cash, once a bitcoin is transferred to another person's address, it cannot be pulled back. Cash theft can be reported to the police and processes exist for investigation and recovery. Such public processes don't exist today for individual theft of bitcoins, as far as I know.
(6) Private: Poor. Truly private exchange is not possible with Bitcoin, as all account (address) transactions are recorded publicly across all servers storing the Bitcoin ledger, also known as the blockchain. Compare this to cash, in which a cash transfer need not be recorded anywhere, and its participants and purchased item can remain unknown. Unlike cash, every bitcoin bears its account transfer history (via the blockchain). Although the transactions are in the clear, the mapping from Bitcoin address to person remains obfuscated, and the object purchased can remain perfectly unknown. In this way, Bitcoin has the benefit of conferring anonymity despite the absence of full privacy. However, if another service manages your Bitcoin addresses, they may require that they know your identity. For example, if you want to exchange bitcoins for dollars, one convenient method would be to provide your bank account for the transfer. In this process, you may be forced to reveal your identity to your wallet service, which might get hacked or otherwise share the information with other parties. If I were the FBI/CIA/NSA, I would definitely have a project that unmasks Bitcoin addresses, linking them to individuals so I could monitor the flow of these tokens to terrorists or other people suspected of significant illegal activities. The bottom line is that if you want privacy using Bitcoin, it isn't simple, you need to be technically savvy, and you need to avoid making casual mistakes, which can be difficult.
(7) Simple to use: OK. As mentioned above, if you want to use Bitcoin as a novice, you will likely trade your privacy in exchange for simplicity. Although the infrastructure is complicated, there are many services available today that hide that complexity and provide a simple user experience for sending and receiving bitcoins. There are even Bitcoin ATMs that accept dollar bills and transfer bitcoins to your Bitcoin address, and, in the opposite direction, dispense dollar bills when you transfer your bitcoins to the ATM's Bitcoin address.
(8) Reliable: OK. If a seller cannot process your Bitcoin sale due to a technical issue (e.g. lost power, phone/computer failure), then no transaction can be completed. Compare this with the dollar, in which a credit card network failure does not prevent one from using physical cash to complete a sale. Some people have implemented physical bitcoins that are real incarnations of digital bitcoin addresses, so this is conceptually a possibility with Bitcoin as well, though as far as I can tell, it hasn't gained much traction among Bitcoin users.
(9) Interoperable: Good. With many markets in existence in many different currencies, it is possible to trade bitcoins in exchange for your local money.
(10) Advantageous: Poor. As far as I can tell, Bitcoin offers 2 distinct advantages over sovereign money. First, bitcoins have proven to be the preferred form of payment in the remote sale of illicit goods, including drugs and weapons. Despite the fact that transactions are not completely private, Bitcoin has succeeded as the platform for illicit exchange that can occur without each party ever physically meeting the other. It seems that people find paying with bitcoins a personally safer and more reliable method than meeting face-to-face. Bitcoin's second advantage is that bitcoins get transferred between accounts (addresses) very quickly, currently within about 10 minutes, 24/7. This is much faster than transferring digital dollars, which can be done by wire (takes hours during the workweek) or ACH transfer (several days). But this doesn't seem to be that big of a need today, though I suppose it could become one in the future. Of course, it is possible that faster methods to transfer digital dollars might also crop up if demanded. Another possible advantage of Bitcoin over digital dollars could be in sending money overseas. With digital dollars, you can do an international wire transfer for about $35 per transaction, and send money to nearly any international bank account. I once sent money to my brother in India this way. Bitcoin is conceivably cheaper, but it remains prone to foreign exchange risk and latency/complexity (e.g. to transfer money from your bank account to a bitcoin wallet will take a few days or require a wire and its associated fee, and getting the money back out from bitcoin to a foreign bank account will again take a few days or require a wire+fee). So it seems that Bitcoin may not be so great for transferring money internationally.
To summarize: of the 10 supporting features a token should have to function as money on a national scale, bitcoins do well on 6 of them, and poorly on the remaining 4: privacy, recourse, stable value, and advantage. Perhaps novel products and features could improve privacy and provide recourse. A stable value seems difficult given the amount of speculation and attention Bitcoin is receiving. But by far the most critical failure is in the advantage category. The need for speed in money transfers doesn't seem critical to most people, and the usage for illicit transactions seems limited to a small subset of individuals within a nation.
Could the bitcoin function in parallel to a domestic money, without the need to supplant it? Countries not in currency crisis seem to rely on only a single currency, not many, due to psychological and infrastructure simplicity. So the likelihood of the bitcoin functioning as a parallel currency seems high only in countries in which there is a currency crisis. However, I suspect that people in such countries generally will not trust bitcoin, which is hard to understand and explain, over the people that they know, who they can establish a new mutual credit system with.
So, in a sense, bitcoins are money, but they are money without a home. Without a home, the bitcoin is not "generally acceptable" anywhere, and therefore fails as practical money, leaving it as a fringe or "theoretical" money. Even if a new country is created and considers using the bitcoin as its national currency, I doubt it will adopt it (or be successful if it does) because of the lack of any control over monetary policy. In existing countries, the network effects of the domestic currency are already too strong to be overcome by or even share significant monetary space with the bitcoin.
To conclude, given the analysis above, I believe that bitcoins don't have much of a chance at becoming money used on a national scale. They are likely to remain a niche medium of exchange, the solace of drug dealers and speculators.
Investing in bitcoins may still make sense, just not because you expect bitcoins to become mainstream money on a national scale. I, for one, am not investing in Bitcoin right now.
---
Acknowledgement:
Thanks to Rosa Cao for early email discussions that helped clarify my thinking!
---
Sources:
Taylor, John B. 1998. Economics. 2nd Edition. - This was the econ textbook I used at Stanford in Econ 1, which was also taught by Taylor.
]]>Comments: ]]>Neha Narula: I'm still digesting what you wrote, but I think you are missing a few things.
Bitcoin is the first cryptocurrency, not the last, and as such, it's not a good idea to ask the question of whether it *as it exists right now* will be successful, but, whether a later iteration (potentially based on bitcoin, potentially not) will be successful. So, really, we want to know two things 1) are there fundamental problems in cryptocurrency design that cannot be fixed and 2) once its fixable problems are fixed, will it be useful?
- #6: Have you heard of Zcash? An anonymous cryptocurrency.
- #5: I think part of the reason cryptocurrencies have the potential to drastically lower transaction costs is exactly because there is no recourse. This increases confidence that a transaction cannot be reversed. An example: let's say I buy a very fancy ming vase from you, and then break it. Now let's say the government decides that the money I used to buy that vase was stolen. Can they reclaim it from you? Who gets made whole, and who doesn't? If there's a risk that a payment won't be final, then that risk will be reflected in the price of the item.
I think their advantage is that cryptocurrencies will enable software-defined payments, without an intermediary. At the moment, all digital money transfer is owned by a private institution (bank, paypal, credit card company, etc). There is no open platform for the transfer of digital money.
nikhil: Hi Neha,
I agree that Bitcoin can be improved on. Part of the point of my analysis was to identify areas that should be addressed, *if* someone wants to make a cryptocurrency that displaces a national currency. There certainly can be other utility asides from usage as a national money, but this is the use case I chose to focus on here.
I think despite the potentially addressable issues with privacy (thanks for the pointer to Zcash) and recourse (perhaps through insurance?), the property of stable value seems hard, in the current speculative climate. Perhaps more importantly, I think more compelling advantages of a distributed, non-sovereign digital currency over a sovereign currency need to be clearly articulated or discovered before non-sovereign currency can displace an established sovereign currency.
You seem to think that a lack of recourse is a good thing. While your specific scenario of stolen money is one case, I think a more common case is buying something and discovering that it is not as you expected, so you want to get your money back. eBay and Amazon implement recourse in these circumstances. If a product is not as described, then they will cover the cost, even if the seller does not accept returns. People clearly prefer this kind of guarantee over the no-recourse approach you seem to favor, even if it does increase costs somewhat.
Another use case for recourse that seems to be a more common occurrence with Bitcoin is straight up wallet theft, due to a thief stealing someone's private key. Imagine if you came home one day to discover that your savings had disappeared, and there was no one to call who could investigate the theft and return the money. At the very least there needs to be something like FDIC insurance for Bitcoin addresses, and it would be even better if there was a specific process to investigate such theft, outside of reporting it to the local police.
Why is it valuable to have "software-defined payments"? What does that even mean? What is the real value in having an open platform for digital money? Just because something is open doesn't mean it will inherently succeed in the market (e.g. Microsoft and Apple OS' are closed systems that dominate the consumer PC market).
Neha Narula: This is a good debate!
Yeah, I don't think I care that much about Bitcoin displacing a national currency. I'm just more interested in what a widely-used digital currency can enable.
By programmable currency, here's what I mean: There's no ubiquitous, common API for money. We have tons of digital money (credit cards, paypal, venmo, ACH), but none of it works together, or if it does, exchange between different forms is slow or incurs high fees. For example, within Europe digital payments work very well, but how hard is it to open a European bank account as an American? Why doesn't my bank work with venmo?
Because there is no cheap, common payments platform, I think there are a lot of applications that have not been built. For example, check out some of the stuff that 21.co is pushing, like renting out your dormant resources. We still don't have micropayments. What if I could do things like easily charge people to use my open wifi network by the byte?
You misunderstand me about recourse -- recourse is incredibly valuable, but the question is at what layer in the money stack does it occur. Ebay and Visa and whatnot make me whole again without necessarily stopping payment or recovering payment from the wrong-doing party -- it's built into their cost structure for them to just occasionally eat these kinds of things. That makes a lot of sense! But if I buy something from a stranger off craigslist with cash and it turns out it wasn't what it seems, I can't go to the federal reserve and demand that they stop the dollar bills I used to pay from circulating. Even if millions of dollars of my cash was stolen I can't do that. Bitcoin seems the same to me -- why should Bitcoin wallets be FDIC insured? Especially if there is no company/bank acting as the entity to be insured? Perhaps we could have individual FDIC insurance but what does that look like?
nikhil: You are making 2 points. The first argues for the value of programmable currency, which can sit on top of any currency, either fiat or crypto. The second argues that recourse isn't always necessary with any currency, as demonstrated when you pay for something using cash and don't receive what you expect to. I will address both points separately (though they are interconnected).
First, I think the reason we don't have general programmable money is not because of an absence of tech, but because of a rejection of risk. So far, banks and governments (and individuals?) have aired on the side of relatively slow money transfer services which allow time for human intervention. This slowness lets banks satisfy anti-laundering and other regulations meant to reduce criminal activity. Additionally, it lets individuals call their bank to report a theft or accidental transfer, enabling the bank to block pending transactions that would have cleared in 2-3 days.
In fact, at the central banking level there is programmable money in the form of the SWIFT system. There, significant thefts have already been demonstrated. Most recently, the SWIFT system was hacked at Bangladesh Bank to authorize $1B in unauthorized transactions from the Bank. The theft was limited to $81M because most of the orders were blocked, supposedly because they misspelled the word "Foundation" in the recipient's name. The orders were (likely) intentionally issued at times when Bangladesh Bank was closed for the weekend, while the Fed was still open to effect the transaction. The Fed even tried to contact the Bank on the phone, but since they were closed, they could not be reached and they authorized some of the transfers nonetheless.
So programmable transfer of fiat currency already exists at the largest scale and carries very high risk, so I suspect that the system will undergo some improvements to reduce that risk, which will invariably cause the slowing of transactions. Cryptocurrencies do not implement any such anti-theft measures, either human review or automated, and I think these would be important to reduce theft and support adoption.
Furthermore, in addition to monitoring for theft, there is monitoring of money transfers for regulatory reasons, including anti-terrorism and anti-laundering. These probably require review of some transactions, further slowing transfer rates. Cryptocurrencies might legally be required to implement these regulations as well, if they became more widely used. This seems difficult, and perhaps even against the anti-government spirit at the source of cryprocurrencies.
To conclude, I don't think general programmable money, on fiat or cryptocurrency, without human approval, stands a chance for 2 reasons. First, there is too much risk of unintentional transfer, including theft and accident. Second, and related, there is a significant amount of regulation that money transfer services must comply with.
To your second point on recourse: if you buy something on craigslist and pay cash, you assume the risk that you may not get what you expect. You can just as easily offer to pay with a credit card via paypal/venmo, and have someone else assume the risk for a fee (aka insurance). The point is that you have flexibility as a user of dollars. With cryptocurrency, you don't yet have that flexibility. And I think this flexibility is yet another feature necessary for wider adoption of cryptocurrency.
It seems that there might be the hope of recourse with cryptocurrency after all. I'm sure you've seen that the DAO was hacked, after raising the equivalent of $150M in ether. WSJ has a brief article about it here: http://on.wsj.com/28Kmatj. I thought all was lost, but interestingly the Ethereum Foundation froze the thieving account and is forking the codebase to restore the stolen ether. I'm surprised that they think they can do this, because it means that they can control the distributed network of miners. Perhaps this is true because the network remains small with limited mixing services. I doubt this could be achieved by Bitcoin, which must have many more miners, many of whom are in China and may not care about theft.
********
To summarize, I think a single additional feature might be necessary for wider adoption of cryptocurrency. Cryptocurrencies may benefit from a second, "slow" coin transfer process which would occur if the transaction must undergo additional review because it triggers (a) concern of theft or (b) regulatory review. For example, transactions above a certain value would be subject to "slow" transfer, or transactions in which the sender wants a slower transaction, which might be a requirement for insurance.
nikhil: An article on WSJ asking the question, "Can Bitcoin become a dominant currency?"
https://www.wsj.com/articles/can-bitcoin-become-a-dominant-currency-1540174021?mod=hp_major_pos18
Jennifer S: Hey Nikhil
I was led into your blog randomly reminded on LinkedIn. And reading your latest post the blind spot experience, and several pieces of article several years back.
Really enjoyed your writing! No matter what topics (varying from science to personal/spiritual experience/ finance), you always put in lots of background and critical thoughts lol :)
Wishing you all the best with the research and hoping you at some time invested in the bitcoin ;p
Cheers
Kirk : So much information. I learned a lot. Gained a understanding that I didn't have before. ]]>
Write Comment]]>
Economicsnikhil2016-05-25T00:50:27-08:00Noise reduction on Epson projectors = Motion Blur
http://nikhil.superfacts.org/archives/2016/04/noise_reduction.html
Occasionally, I discover that something that should be known online is not. And occasionally when this happens, I figure out the solution. This happened yesterday, so I wanted to record it on the net.
Internet, this one is for you.
About a month ago, I bought a refurbished LCD projector, an Epson Powerlite Home Cinema 2030, to setup a home theater in the living room of our new home. But when I plugged in my old Sony Blu-ray player, the video was fullof motion blur or lag. When something moved on the screen, there was a trailing ghost image, making it hard to see anything clearly. This blu-ray player had worked fine in Boston on the DLP projector we used there, so I thought it might be incompatible with my new LCD projector.
To rule out the projector as the cause, I plugged in my laptop with its blu-ray player, and the picture looked sharp and crisp without any motion lag. So, I thought, it must be a problem with our blu-ray player. I googled to see if others had had this issue, and all I could dig up was that LCD projectors and TVs are known to have some motion blur, apparently because the LCD can't refresh fast enough. But no one was describing my strange issue where my laptop played beautifully and the dedicated blu-ray player did not, and no one seemed to be returning their LCD projector because of it.
So I went to Best Buy, bought a new blu-ray player, came home, tested it. Fail - still see motion blur. Back to Best Buy, on to player #2. After buying, testing, and returning 3 blu-ray players over 2 weeks or so, Best Buy flagged my account and now warned me that I may not be able to return anything for awhile. Oh well, time to use Becca's credit card. Same problem with the 4th player, a Samsung. So now I'm thinking, it must be the projector + blu-ray combination.
I rarely call tech support, because the people on the other line often know less about their product than I do. But I had run out of options. I called Epson tech support, and they told me to set the "Image Processing" setting from Fine to Fast. I had tried this before and not seen any improvement, so I reluctantly made the change. Luckily, this time I changed the setting right after turning on the projector and blu-ray player. Turns out, if you change Image Processing while a Blu-ray is playing, the projector ignores the change, even though it says the setting has been changed. The Blu-ray player has to recently have been turned on and on its home screen, and only then does making the change actually take effect! I knew something different had happened because the projector menu got enlarged. And then when I went to play the blu-ray, no more motion blur! It finally worked!
But I was a bit puzzled and concerned that having image processing set to Fast would compromise the picture quality. Fiddling a bit more, I found that the Image Processing setting actually wasn't the culprit. It was the stupid "Noise reduction" setting. By default, Fine image processing sets noise reduction to 3, its max value. The standard algorithm for reducing noise in images is to blur everything just a bit, smoothening out the colors. But it turns out that this projector isn't actually powerful enough to do this at 30 fps without compromising the picture quality by introducing motion blur. Lowering noise reduction down to 1 or Off removed the motion blur altogether! Noise reduction changes can be made while a blu-ray is played and you see an immediate effect.
Success at last, after a month of buying and returning blu-ray players! Epson, your noise reduction sucks big time. One last trip to Best Buy, to trade this Samsung blu-ray player for a Sony, because I like the lower contrast image of the Sony more.
Anyhow, hopefully this little tip will help a Google searcher save some time and frustration in the future. ]]>Comments: ]]>Siddharth Bhatla: Maybe it is the higher bit-rate of Blu-ray player that's the actual culprit for overloading the frame-buffers/RAM of the projector's image processing unit....
Turns out that noise reduction is required more in amateur videos whose bit-rate is naturally set lower ( upto 20 Mbps for Phone Cameras ) by camera designers to save memory for longer videos..
Conversely, Professionally created footage, has higher bit-rates ( 50-70 Mbps for High End DSLRs ) and Blu-ray can support upto 40 Mbps, and Imperfections like Noise is dealt with in Production Stage so we don't much of it in Broadcast-ed / Distributed Media... So Designers at EPSON may have taken that assumption while including those Noise Reduction settings in the projector's menu.
Glad to Hear from you !
Siddharth Bhatla
siddharthbhatla_2000@ymail.com
Anonymous: Thank you ! ]]>
Write Comment]]>
Technologynikhil2016-04-16T18:44:58-08:00<![CDATA[<i>Money: The Unauthorized Biography</i> by Felix Martin]]>
http://nikhil.superfacts.org/archives/2016/03/book_notes_mone.html
It has been a very long time since I last wrote a Book Notes entry (in fact, the last one was in 2007). During PhD grad school (2007-2015), I didn't write any Book Notes because I barely read books, as journal articles fully absorbed my attention. Now that grad school is finished, we've finished our move from Boston to Oakland, and my time is unstructured once again, I no longer have the attention span for the disorganized presentation of journals and returned to that old standby, the book.
As some of you may know, I have been slightly very obsessed with understanding the true nature of money: how does money come into existence, and how does its manufacture influence the economy, from pricing to economic volatility. I have been thinking about this question since Dec 2013. Surprisingly, while trying to research how money is created in modern American society, I found very little written about the topic in economics books. I went to the Sloan Business School's library at MIT, rustled through the shelves on macroeconomics, and came up virtually empty-handed on a detailed description of how money is created. Sure, a country's central bank (in our American case, the Federal Reserve) generates money out of thin air, "printing" it both physically and virtually, but how exactly does this money get put to work, from start to finish? And if all money is created as debt (which it is), then how can the system not fail if that debt requires interest payments, which must be paid with money which is itself borrowed? Isn't this a pyramid scheme, which at some point must collapse? And might this not be the fundamental reason that we have recurring periods of economic crisis, during which massive debts must be forgiven? I have much to say about these questions, but that will have to wait for a future blog post.
Due to this paucity of written material on the nature of money, I was very happy when I discovered Felix Martin's recent book, entitled Money: The Unauthorized Biography. I picked it up at the Harvard Bookstore in Cambridge last month and now I've finally finished it.While it doesn't answer all the questions of money I posed above, it nonetheless provided a fascinating historical account of money and attempted to seriously determine what money actually is. While I don't agree with much of the author's idealogy, the historical incidents are quite illuminating as to what money truly is and how societies have made use of it.
As is my Book Notes style, below you will find sections quoted from the book itself, which I found interesting enough to underline while reading the book. Pages where the quotes can be found in the paperback edition are written in parentheses. I will also provide my own commentary as I see fit, which will be indicated by bullets (•) or brackets [].
I've bolded the quotes I find especially salient and insightful, so just skim those if you want an even quicker read of the book.
Finally, Martin discusses the viability of Bitcoin as money very briefly at the end of the book, essentially dismissing it. I plan to take up this question, in addition to articulating my understanding of what makes something money, in greater detail in a later blog post.
====================================================
Book Notes from Money: The Unauthorized Biography
====================================================
written by Felix Martin
published in 2013
CHAPTER 1: WHAT IS MONEY
- "Coins and currency, in other words, are useful tokens to record the underlying system of credit accounts and to implement the underlying process of clearing... Money is the system of credit accounts and their clearing that currency represents." (14)
- "At the centre of this alternative view of money - its primitive concept, if you like - is credit. Money is not a commodity medium of exchange, but a social technology composed of three fundamental elements. The first is an abstract unit of value in which money is denominated. The second is a system of accounts which keeps track of the individuals' or the institutions' credit or debt balances as they engage in trades with one another. The third is the possibility that the original creditor in a relationship can transfer their debtor's obligation to a third party in settlement of some unrelated debt." (27)
- "Whilst all money is credit, not all credit is money... Money, in other words, is not just credit - but transferable credit." (27)
- "For sellers to accept buyers' IOUs in payment, they must be convinced of two things. They must have reason to believe that the debtor whose obligation they are about to accept will, if it comes to it, be able to satisfy their claim: they must believe, in other words, that the money's issuer is creditworthy [this is credit risk]. This much would be enough to sustain the existence of bilateral credit. The test for money is more stringent. For credit to become money, sellers must also trust that third parties will be willing to accept the debtor's IOU in payment as well. They must believe that it is, and will remain indefinitely, transferable - that the market for this money is liquid [this is liquidity risk]. Depending on how powerful are the reasons to believe these two things, it will be easier or harder for an issuer's IOUs to circulate as money... What matters is only that there are issuers whom the public considers creditworthy, and a wide enough belief that their obligations will be accepted by third parties." (28-29)
CHAPTER 2: GETTING MONEY'S MEASURE
- "When it comes to money itself - rather than the tokens that represent it, the account books where people record it, or the buildings such as banks in which people administer it - there is nothing physical to look at." (33)
- "These three simple mechanisms for organising society in the absence of money - the interlocking institutions of booty distribution, reciprocal gift exchange, and the distribution of the sacrifice - are far from unique to Dark Age Greece." (37)
- "...Mesopotamia witnessed the invention of three of the most important social technologies in the history of civilization: literacy, numeracy, and accounting." (40)
- "Correspondence-counting requires no numerical sophistication whatsoever, merely the ability to check whether are the same." (42)
- "Henceforth, a sheep would not be represented by a conical token kept in an account box, but by the triangular impression of such a token on a clay tablet... The ancient system of three-dimensional objects had been translated into a new system of two-dimensional symbols... Instead of writing five sheep symbols to signify five sheep, separate symbols for the number five and the category sheep were introduced." (43)
- "Why was it that this extraordinary commercial civilisation [of Mesopotamia], the most advanced economy that the world had ever seen, the society that invented literacy, numeracy, and accounting - did not invent money?" (45)
Martin raises this question, but then does not answer it convincingly. My sense is that while the Mesopotamians excelled at abstractive, symbolic processes, they somehow were not able to abstract the next step, to the genericization of value.
- "When fathoms, furlongs, leagues and hands were originally devised, for example, there simply was no unversal concept of linear extension."
This statement forms a bit of the bedrock for Martin's idea that once people recognized that all objects can be measured against each other by noticing their abstract value, the need for money became clear, as the yardstick for measuring an object's value. However, for the other kinds of measurement, such as length as described in the quote above, Martin does not make a convincing argument that the abstract concept of length was lacking when many different measurement units for different kinds of objects were in use. This is a huge, unsupported stretch, one that's hard for me to swallow and which I strongly disagree with. I think it more likely that the people measuring depths in the ocean were simply different people than those measuring the lengths of fields, and so used different jargon (as frequently occurs in different, isolated fields of work today).
CHAPTER 3: THE AEGEAN INVENTION OF ECONOMIC VALUE
Of the three classical functions of money (medium for exchange, unit of account, store of value), I think the most critical and unique to money itself is the function as a medium for exchange. It is this function that enables "liquidity", that is, the ability to convert an asset into one or many other assets, with money serving as a transient lubricant. Without a medium for exchange, this conversion would be difficult or impossible. The medium for exchange function of money also includes the credit creation of money, in which one party trades their future work for another's current work product. Although it is not quite as obvious, this is also an exchange of assets - however, this exchange in practice requires accounting, highlighting the practical relevance of the second property of money, as a measure used for accounting.
The evolution of a medium for exchange:
1) An item of innate social value (e.g. gold)
2) An item that represents something of innate social value (e.g. a bill that can be exchanged for gold)
3) An item that does not represent something of innate social value (e.g. a bill that can only be exchanged for another bill; a virtual coin, i.e. bitcoin)
- "If the dollar is a unit of measurement, what does it measure? The answer, on the face of it, is simple: value, or more precisely, economic value." (52)
I prefer the following explanation of the dollar: What is a dollar? A dollar is a unit of measurement that measures the value of something in the context of trade. Money comes in different currencies, and all are units by which to measure value.
- "The spread of money's first two components - the idea of a universally applicable unit of value and the practice of keeping accounts in it - reinforced the development of the third: the principle of decentralised negotiability." (61)
- "...Liturgies - the ancient, civic obligations of the thousand wealthiest inhabitants of the city to provide public services ranging from choruses for the theatre to ships for the navy." (62)
CHAPTER 4: THE MONETARY MAQUIS
- "By July [2002], nearly one in ten of the adult population [of Argentina] was discovered to be using the Credito - a mutual credit money issued by the local exchange clubs on its own, independent standard... Until the peso regained its monopoly over the monetary franchise, the government could not be in control of the country." (69-70)
- "[Mutual credit] is a credit not against the original issuer, but against society as a whole - or against the body politic of a credit network's members. There are two basic preconditions for the successful functioning of such a system. First every member must maintain his creditworthiness. Only then can society be confident in the value of his money. Second, all member must know one another, if not at first hand, then at second; or have some other grounds, by convention or compulsion, to accept society's word for an unknown member's credit." (73)
- "[In a monetary utopia,] everyone would issue their own IOUs, those IOUs would be readily accepted by all, and the entire economy would function as a vast mutual credit network. But men are no more angels in economics than in politics... Money on any significant scale can therefore never consist of liquid credit accumulated against "society". The alternative is obvious - and was so at money's birth. Money will naturally consist of liquid credit accumulated against society's most concrete manifestation: the sovereign." (73-74)
I don't think I agree with this reasoning for why the sovereign generally gets to determine which token functions as money in society. Instead, I believe that the sovereign decides because (1) they are the biggest payer and receiver of credit in the economy as a whole, and (2) they represent society, at least in the case of democracy. It is (1) that essentially allows them to dictate what the credit token will be, and by using it to pay workers and to get paid taxes, it spreads to other domains of the economy as a matter of convenience. Sovereign money might be displacable if another institution came to occupy a larger fraction of the economy than the government did, I suspect.
- "In purely practical terms, sovereigns makes a lot of payments." (74)
- "Money's value [in some monarchies] was directly proportional to how much of it was in circulation compared to the quantity of goods available. The role of the soverign, therefore, was to modulate the quantity of money available in order to vary the value of the monetary standard in terms of those goods. He [the king] could choose a deflationary policy - "if nine-tenths of the kingdom's currency remains in the hands of the ruler and only one-tenth circulates among the people, the value of money will rise and prices of the myriad goods will fall"; or an inflationary one - "he tranfers money to the public domain, while accumulating goods in his own hands, thus causing the price of myriad goods to increase ten-fold" - depending on the needs of the economy." (78)
Sounds a lot like the Fed of today...
Balance the guarantee afforded by cash with the vulnerability it opens to the whimsy and attack of the government.
CHAPTER 5 - THE MONEY INTEREST
- "In the poet Ovid's satirical textbook for young lovers, The Art of Love, he warns the prospective Lothario that girlfriends need presents - and it is no good making the excuse that you have no cash on hand, because you can always write a cheque." (83)
- "Under normal circumstances, when seigniorage [payment made to the government] was levied only on the gradual increase in the coinage supply demanded by a growing monetary economy, the revenues [payments made in exchange for turning metal into coins] were relatively modest. But when the need arose, a sovereign could raise enormous sums by crying down or even demonetising altogether the current issue of the coinage and calling it in for re-minting off a debased footing." (89)
- "At some point, the new money interest was bound to assert itself against the sovereign's perceived excesses." (89)
- "The soverign, Oresme pronounced, "is not the lord or owner of the money current in his principality. For money is a balancing instrument for the exchange of natural wealth... it is therefore the property of those who possess such wealth." (92)
- "If people wanted coins, they could bring silver to the Mint and have it coined, with only minting costs and a minimal seigniorage tax to pay. The problem was that this laissez-faire solution was unlikely to worrk in practice, because there was no reason to suppose that the arbitrary supply of precious metal would necessarily accord with the demand for money." (93)
CHAPTER 6 - THE NATURAL HISTORY OF THE VAMPIRE SQUID
- "Less and less were they [mercantile fairs] opportunities for the physical exchange of goods. More and more, they were occasions for the clearing and settlement of credit and debit balances accumulated in the course of international trade over the preceding months... It had become the most important market in Europe not for goods, but for money." (97-98)
- "The great merchant houses of Europe had rediscovered the art of banking - how to produce and manage private money on an industrial scale." (100)
- "If a great merchant substituted his word for that of a local tradesman, an IOU that might previously have circulated at most within the local economy coud be transformed into one that could circulate anywhere where the great merchant's prestige was acknowledged. A pyramid of credit could be constructed, with the obligations of local tradesmen as the base, large wholesalers in the middle, and the most exclusive, well-known, and tight-knit circle of international merchants at the top." (101)
Successful Banking depends on Successful Branding!
- "It was here - in the creation of a private payments system - that the invention of modern banking originated." (101)
- "Any IOU has two fundamental characteristics: its creditworthiness - how likely it is that it will be paid when it comes due - and its liquidity - how quickly it can be realised [converted to money], either by sale to a third party or simply by coming due if no sale is sought. The risks associated with any promise to pay depend upon these two characteristics. Accepting a promise to pay in a year's time entails more risk than accepting a promise to pay tomorrow - a lot more can go wrong in a year than in twenty-four hours. This is the dimension of liquidity risk - so called because unless it can be sold in the meantime, a private promise to pay only becomes liquid at the moment it is settled in sovereign money. Then there is the possibility that the IOU's issuer will not be able to pay at all, regardless of the timeframe... This is the dimension of credit risk." (102-103)
Seems to me that even if there is credit risk, then that will in turn affect and increase liquidity risk. Why buy something now if you think the debtor is unlikely to pay back its debt? On the other hand, even if there is no credit risk, there could be significant liquidity risk.
- "The whole business of banking resolves into management of these two types of risk, as they apply both to a bank's assets and to its liabilities. Banks transform uncreditworthy and illiquid claims on the assets and income of borrowers into less risky and more liquid claims - claims which are so much less risky and so much more liquid that they are widely accepted in settlement of debts." (103)
- "Strip a bank's balance sheet back to its barebones, and the simplest form of banking, the form practised by the most risk-averse of banks, is the short-term financing of trade. In this kind of banking, credit risk is minimal: loans are usually extended simply to cover the purchase and transport of goods for which a sale has already been agreed, and the goods themselves are often used as collateral. With sufficient insurance, the bank might even eliminate the credit risk altogether. The risk it can never get rid of, however, is liquidity risk...[The banker's art] is nothing more than ensuring the synchronization, in the aggregate, of incoming and outgoing payments due on his assets and liabilities - which are themselves, of course, the aggregated liabilities and assets of all his borrowers and creditors." (103-104)
- "By buying such a bill of exchange, the Italian merchant achieved two things. First, he accessed the miracle of banking: he transformed an IOU backed by ony his own puny word for one issued by a larger, more creditworthy house, which would be accepted across Europe [an example of banking as branding]. He transformed his private credit into money [generally accepted credit]. His second achievement was to exchange a credit for a certain amount of Florentine money into one for a certain amount of the money of the Low Countries where he was making his purchase [foreign exchange]." (106)
- "The end result [of bill-of-exchange banking] was to overcome a previously insurmountable series of obstacles. The exchange-bankers would accept the importer's credit, knowing him and his business well from the local market. Meanwhile, the supplier in the Low Countries would accept the exchange-banker's credit as payment, knowing that it would be good in its turn to settle either a bill for imports or for some local transaction - and satisfied that he was being paid in the local money. Of course, the banker ran the risk that the exchange rates of the two sovereign moneys against the imaginary ecu de marc [the exchange banker's internal community currency] might change in between his issuing the bill of exchange and its being cashed in the Low Countries, but he made sure that his fees and commisions made this a risk worth taking... The exclusive cadre of exchange-bankers would convene alone to agree on the conto: the schedule of exchange rates between the ecu de marc and the various sovereign moneys of Europe. This schedule was the pivot of the entire financial system, since it was at these exchange rates that any outstanding balances had to be settled on the final day of the fair - the "Day of Payments" - either by agreement to carry over the balances to the next settlement date, or by payment in cash." (106-107)
Could Bitcoin function as a modern ecu du marc?
CHAPTER 7: THE GREAT MONETARY SETTLEMENT
- "Monetary society, [Oresme] wrote, was nothing other than "the most effective bridle ever was invented against the folly of despotism."" (113)
- "What was new about the Projector William Paterson's proposal was that this Bank of England would in effect be a public-private partnership. The Bank's primary role would undoubtedly be to put the sovereign's credit and finances on a surer footing. Indeed, its design, governance and management were to be delegated to the mercantile classes precisely in order to ensure confidence in its operation and credit control. Bur in return the sovereign was to grant important privileges. Above all, the Bank was to enjoy the right to issue banknotes - a license to put into circulation paper currency representing its own liabilities, which would circulate as money. There was to be, quite literally, a quid pro quo... If they and the private interest money they represented would agree to fund the king on terms over which they, as Directors of the new Bank, would have a statutory say, then the king would in turn allow them a statutory share in his most ancient and jealously guarded prerogative: the creation of money and the management of its standard." (117-118)
- "Without the state, the Bank would have lacked authority; without the Bank, the state would have lacked credit." (119)
- "This compromise [between private bankers and the sovereign to create the Bank of England] is the direct ancestor of the monetary systems that dominate the world today: systems in which the creation and management of money are almost entireley delegated to private banks, but in which sovereign money reamins the "final settlement asset," the only credit balance with which the banks on the penultimate tier of the pyramid can be certain of settling payments to one another or to the state. Likewise, cash remains strictly a token of a credit held against the sovereign, but the overwhelming majority of the money in circulation consists of credit balances on accounts at private banks." (120)
- "Before Oresme, money had been understood implicitly as a tool of government: part of the sovereign's feudal domain, and an instrument of his policy. Oresme had challenged this, and proposed an alternative objective of monetary policy - to supply the needs of the community." (120)
CHAPTER 8: THE ECONOMIC CONSEQUENCES OF MR. LOCKE
- "The value of money depended not on the stuff that coinage was made of but on the creditworthiness and authority of the sovereign who stood behind the tariff that specified the nominal value of the coin." (129)
- "Plato called it [money] a "symbol that exists for the sake of exchange... It exists not by nature but by convention."" (130)
- "The feudal lords who had been the prime beneficiaries of traditional [non-monetary] society had been bewitched by the magic of money. Their love of luxury had made them encourage the monetisation of their feudal rents: "thus, for the gratification of the most childish, the meanest and most sordid of vanities, they gradually bartered their whole power and authority."" (135)
- "The founders of the Bank of Englans believed that their marriage of private banking and sovereign money had unleashed the greatest force for economic and social progress in history." (136)
CHAPTER 9: MONEY THROUGH THE LOOKING-GLASS
- ""Financial crises have tended to appear at roughly ten-year intervals for the last 400 years or so." [Charles Kindleberger said]" (137)
- "All financial contract must be fair to be sustainable." (140)
An interesting definition of fair - if a contract sustains, is it necessarily fair?
- "[Keynes:] "For nothing can preserve the integrity of contract between individuals except a discretionary authority in the State to revise what has become intolerable."" (140)
- "Money promises to organize society in a manner that combines freedom and stability. This it will achieve first by transforming social obligations - traditional rights and duties that are fundamentally incommensurable with one another - into financial obligations - assets and liabilities all measured in the same units of abstract economic value; and then by making these financial obligations liquid - allowing them to be transferred from one person to another." (141)
- "As the great recoinage debate had revealed, Locke's understanding of money represented a complete reversal of perspective from the vantage point occupied by Lowndes and his practitioner friends. It was obvious to them that the pound was just an arbitrary standard of economic value. It had lost value against silver - there had been inflation, and the price of silver had risen. The coinage had lost its silver content [by being shaved down by the populace] because the pound had lost value. Locke, by contrast, thought this was getting it completely the wrong way around. A pound was nothing but a definite weight of silver bullion. The pound had lost its value because the coinage had lost its silver. The old understanding had been that money is credit, and coinage is just a physical representation of that credit. The new understanding was that money is coinage, and credit is just a representation of that coinage." (142)
This is interesting, because it shows that what the people thought was what mattered. They did not think of the pound as being a definite amount of silver, but a more general intermediary used in trade. If the value of that intermediary went down relative to silver, than the people shaved down the coins to collect the extra silver.
CHAPTER 10 - STRATEGIES OF THE SCEPTICS
Money is an organizing power for society insofar as it controls consumptions to prevent scarcity
- "Money's ability to deliver personal freedom - from traditional social obligations, even from family obligations - was an exhilirating prospect." (155)
- "[In early Soviet Russia] the job of banks was not to screen projects for finanicng and monitor loans once granted. It was simply to create money to order as soon as a payment instruction had been issued from an engineer's desk. The process was automatic... The inevitable result of this relegation of money to a passivce role was an explosion in its issuance. The engineers were in charge, and there was no incentive to listen to the irrelevant bankers' whining about finanical viability...since it was production and not money that mattered, who cared?" (162)
CHAPTER 11: STRUCTURAL SOLUTIONS
- "The more people use money to preserve their security, the less that money generates wealth and facilitates mobility... Economic slumps occur, [Law] explained, when "[s]ubjects...hoard up those Signs of Transmission as a real Treasure, being induced to it by some Motive of Fear or Distrust."" (167)
- "[Law argued that] the sovereign issuer of money must have the ability to vary the supply of money to match the needs of private commerce, public finance, and the balance between private creitors and debtors...one which allows discretion in the issuance of money." (168)
France moved off of the gold standard in the 18th century. (170)
- "Law finally achieved an unprecedented and never-to-be-repeated feat: a comprehensive swap of government debt for government equity." (172)
- "The monetary standard was now the elusive creature of the sovereign - so that if the economy, and thereby the Company [which had convinced everyone to exchange their government bonds for company equity], fell on hard times, the value of the Bank's money could fall to reflect this." (172)
- "The problem with conventional sovereign money was that it consisted of financial claims of certain value backed by revenues whose value was intrinsically uncertain... If the economy prospered, the sovereign's tax revenue grew, his credit improved, and his bonds would pay as promised... Rather than pretending to his subjects that he can magic away the uncertainty inherent in economic activity, better for the sovereign to give them access to its proceeds directly - and by the same token, make them bear the risks. With government equity - shares in thr Mississippi Company - this could be done directly. With transferable sovereign credit on a fiat standard - notes issued by the Royal Bank - it could be done at one remove." (173)
- "All income and wealth flows in the end from the productive economy - and it is claims on this income alone that money ultimately represents... The simpler way to acknowledge this fact of life is to transform the fixed financial claims that are generally used as money - otherwise known as debt - into variable ones - otherwise known as equity... [one mechanism would be for] a corporation that owns all the assets of the state, including its rights to collect taxes, in which citizens can own shares." (175-6)
This is an interesting idea, and one which Law implemented in France in the 18th century, but that ultimately failed because equity is vulnerable to bubbles in value, and this variability was too much for a money system.
Monetization of social obligations allowed for social mobility.
CHAPTER 12: HAMLET WITHOUT THE PRINCE: HoW ECONOMICS FORGOT MONEY...
- "[Overends] had evolved naturally into merchant bankers by borrowing on their good name in London and lending to the local sheep-farmers... A potential borrower in the provinces would bring his bills to Overends for scrutiny. If Overends liked the credit, they would find a London commercial bank that would lend against security of the bill - a procedure called "accepting" it... Bill-broking became big business, and the market in debt securities that they intermediated became the governing mechanism of the Industrial Revolution... By the 1850s, [Overend, Gurney]...had a balance sheet ten times larger than those of the two biggest banks in Britain combined." (190-1)
- "[Overend] made a host of other long-term, speculative investments, the only unifying feature of which was that every one was funded, as was the way with the bill brokers' business model, by deposits from the commercial banks that could be withdrawn on demand." (193)
- "But in the end, it as the oldest trick in the City's books that was chosen: an initial public offering that would transform the [Overend] partnership into a public company and thereby offload the problem on to that perennial savious of the City insider's bacon - the general public." (193)
Is this what is happening with the IPO of Editas?
- "And what Bagehot saw as the most basic reality to be grasped about the modern monetary economy was that the conventional understanding of money as gold and silver - the understanding adopted by habit by the man in the street, and the one promoted by academic economists of the day - was confused. The slightest acquaintance with Lombard Street [where Overend was] revealed that the money overwhelmingly uses by businessmen was by and large private transferable credit: above all, bank deposits and notes. "[T]rade in England," he explained, "is largely carried on with borrowed money."" (198)
- "If money is in essence transferable credit - rather than a commodity medium of exchange, as the academic economist insisted - then fundamentally different factors explain the economy's demand for it. Meeting demand for commodities is a simple matter of ensuring a sufficient supply on the market. When it comes to transfeable credit, however, volume alone is not enough: the creditworthiness of the issuer and the liquidity of the liability come into play." (198)
- ""Credit is an opinion generated by circumstances and varying with those circumstances," so that genuine insight into the functioning of the economy requires an intimate familiarity with its history, its politics, and its psychology - "no abstract argument, and no mathematical computation will teach it to us" [wrote Bagehot]." (199)
- "The first step here was to understand that although all money is transferable credit, there is one issuer of money whose obligations are, under normal circumstances, more creditworthy and more liquid than all the rest: the sovereign, which in the moden financial system had delegated its monetary authority to the Bank of England... The Bank had married the commercial acumen of one privileged set of private bankers with the public authority of the sovereign to render the Bank's money both creditworthy and universally transferable... Just as the sovereign had lent its unique authority to the Bank, so the Bank had over time got into practice of lending its authority to the universe of other banks... "[a]ll banks depend on the Bank of England, and all merchants depend on some banker."" (200)
All of this discussion of sovereign money and bank money shows that there is a hierarchy of money/credit.
- "This remarkable monetary infrastructure was, Bagehot explained, the operating system of the Industrial Revolution, and what distinguished Britain from every other country in the world." (201)
- "[Bagehot's] first and most basic prescription [to avoid financial crisis] was that he central bank''s roles as the lender or broker of last resort should be made a statutory responsibility, rather than left to the directors' discretion... "in time of panic [the Bank] must advance freely and vigorously to the public out of its reserve."" (202-3)
Since money is a special type of credit/debt (one which is liquid), this policy amounts to selling productivity expected in the future to restore confidence today.
- "The bank should not try to make nice distinctions between who is insolvent and who merely illiquid in the heat of a crisis. It should lend "on all good banking securities, and as largely as the public ask."... Bagehot therefore proposed his third principle to ward off this risk [which is that, if backstop money is always available, banks will make credit available to those who are not creditworthy]. Emergency lending "should only be made at a very high rate of interest... [to] operate as a heavy fine on unreasonable timidity, and... prevent the greatest number of applications by persons who do not require it."" (203)
This is essentially the policy adopted by the Fed during the 2008 financial crisis.
CHAPTER 13: ... AND WHY IT IS A PROBLEM
- "The conventional understanding of money led the classical economists to diverge dramatically from the views of Bagehot in three areas. The first was the correct principles for monetary policy in a crisis. If the classical conception of money was correct - if money was gold and silver alone - then although everyone might want it in a crisis, there was only so much to go round. The Bank of England should therefore protect its hoard by refusing access, or raising the rate of interest at which the Bank would lend out its gold... [but] what was in short supply in a crisis was not gold, but trust and confidence - which the central bank had a unique ability to restore by standing ready to swap the discredited bills of private issuers for its own sovereign money." (205-6)
- "Thomas Joplin had summed it up concisely: "[a] demand for money in ordinary times, and a demand for it in periods of panic," he had written, "are diametrically different. The one demand is for money to put into circulation; the other for money taken out of it." (208)
- "There is no guarantee that, in the aggregate, supply will always equal demand, for the simple reason that in a monetary economy, rather than having to buy goods and services with their income, people can hold money instead. When prospects look grim, that is exactly what people choose to do in spades - and only the safest and most liquid money, the money of the sovereign, will do." (212)
- "The insight of Bagehote, and Joplin and Thronton before him, [was] of the importance of liquidity as a distinct property of credit - the property which makes it money when it exists, and inert bilateral credit when it does not... The sovereign's liabilities enjoy a degree of liquidity to which no private issue can aspire." (217)
So, liquidity can be quantified as the probability that another member of your society will accept your bill or note as payment. This is nearly 100% with sovereign money, and lower for all other kinds of money.
CHAPTER 14: HOW TO TURN THE LOCUSTS INTO BEES
- "The U.S. spent 4.5% of GDP recapitalizing banks - equal to its entire annual defence budget in the midst of a major war." (230)
- "[The banks'] business was - just as it had always been - to manage liquidity and credit risk. But if they proved unable to synchronise their payments [of term loan payments in and demand deposits out], the central bank would step in with liquidity support. And if their loans went bad and their equity capital was too thin, the taxpayer would backstop their credit losses. The consequences were, in retrospect, utterly predictable. Around the world, banks had grown in size, reduced their capital buffers, made riskier loans, and decreased the liquidity of their assets." (230-1)
- "In November 2009, a year after the collapse of Lehman Brothers, total sovereign support for the banking sector worldwide was estimated at some $14 trillion - more than 25% of global GDP. This was the scale of the downside risks, taxpayers realized, that they had been bearing all along - whilst all the upside went to the shareholders, devt investors, and employees of the banks themselves." (231)
- "[With the establishment of the Bank of England in 1694,] the private bankers got liquidity for their banknotes. The crown's writ, unlike their own, ran throughout the land, and money that had its blessing could enjoy universal circulation. In return, the bankers provided the financial acumen and the trusted reputation in the City that enhanced the crown's credit-worthiness. In modern terms, the crown provided liquidity support to the Bank, while the Bank provided credit support to the sovereign." (233)
credit risk is the risk that a borrower will repay their loan
liquidity risk is the risk that another person will accept the loan as payment
seems like you can have low credit risk (a guaranteed repayment) with high liquidity risk (no market exists for the asset class, or the creditor has a bad name and no one wants to hold his debt)
can you have high credit risk with low liquidity risk? seems more difficult
in general, these two risks seem well-correlated
CHAPTER 15: THE BOLDEST MEASURES ARE THE SAFEST
- "The skeptical tradition has understood since ancient times that a critical prerequisite for the sustainability of monetary society is therefore the safety valve of a variable monetary standard. So long as citizens permit the sovereign a discretionary power to recalibrate the financial distribution of risks by adjusting the monetary standard when it becomes unfair, sovereign money can work." (249)
- "The US economist Robert Schiller... has for many years urged sovereigns to share with investors the risk to the public finances inherent in uncertain economic growth by issuing bonds that pay interest linked to GDP." (252)
Overall, this chapter was unclear, vague, imprecise, and of little value as he treated complex topics as simple ones that follow his assertions and assumptions.
CHAPTER 16: TAKING MONEY SERIOUSLY (SUMMARY CHAPTER)
- "To be precise, you explained that, in essence, money comprises three things: a concept of universally applicable economic value [store of value?]; a system of account-keeping whereby that value can be measured and recorded [unit of account]; and the principle of decentralised transfer, whereby that value can be transferred from one person to another [medium of exchange]." (257)
- "You explained that a dollar, a pound, a euro, is not a physical thing but a unit of measurement." (258)
- "The first [point] was that the concept of universal economic value is just like a physical unit of measurement: the extent of its applicability, and what its standard should be, is properly determined by what it is used for. But the second [point] was that universal economic value is also different from a physical unit of measurement. It is a property of the social rather than the physical world - it's the central component of a technology for organizing society, as you put it - so that its standard needs to be political as well." (258)
- "Anyone can issue their own money - the problem is getting it accepted." (272)
It is this acceptance issue that will determine whether Bitcoin or anything else claiming to be money can actually make it as Money (with a capital M).
EPILOGUE
In this epilogue, Martin very briefly evaluates the viability of Bitcoin as a successful Money. His overall judgement is that it will not succeed, due to the reason quoted below. I found his analysis superficial, as it was likely written only so that they could put "cryptocurrency" on the cover of the new book edition.
- "Yet as this book has shown, [bitcoin] represents a backwards step in the evolution of money, not a revolutionary advance. To achieve widespread acceptance, a money's standard of value must strike a compromise between a wide range of interests [as observed during the creation of the Bank of England] - and just as importantly, it must be flexible over time... Nevertheless, it seems destined to remain an iron law of monetary history that the money which will win the widest acceptance is the one whose standard satisfies the most people - and which those people can adjust if they need to." (277)
-=-=-=-=-=- ]]>Comments: ]]>Ramaswamy: Very detailed notes. Very helpful for me as I was writing the review of the book for my blog investments.manofallseaso s.com
Thank you
Ram
yt: thank you so much for the notes!
helps a lot with my essay.
Kirk Carlson : I skim through a portion of. It in a few areas. I guess that makes sense in my head. Definitely want to sit down and read through it all. Life has a wave. I don't know, setting the. Tone. I like the idea of continuing talks with you. Definitely like the idea of writing in my future rather than digging ditches and being dependent on other people. I also hope that i'm not crazy in making this statement. I will get to reading this in the next few hours and get back to you. But I'm really hoping that just in what I saw is that we continue talking for a while and eventually I continue to write and somewhere along the way. I've got a whole lot of money. That's gonna be coming in and taking care of my family. And everything, so. I know a whole lot of money can mean a lot of different things to a lot of people Thanks to a lot of different people, but if I'm right and you've been following me, then you know how I live and what money I'm used to. Forgive me for not editing voice. Recording
Kirk : I never looked at it that way.I always looked at it like the government was bailing out these companies and we are all struggling and I guess I never thought about how much they print money to protect economy as a whole and how larger companies are in the position to spread it or at least keep people employed. I might need to read that again. ]]>
Write Comment]]>
Economicsnikhil2016-03-19T22:34:29-08:00Third time around, has anything changed?
http://nikhil.superfacts.org/archives/2016/02/third_time_arou.html
I am now on a break from working a specific job, the third such break of my life.
My first break came in 2002, after graduating from college. From June until October, I had all my time to myself. With Dave, I tried to start a company selling live concert CDs at the end of shows, called Music Mint. I wasn't that into it, and it didn't go anywhere. I also helped Sachin a little on a project for recording music from internet radio, called Wimpus. Sachin released that and I loved it. And I spent most of my time with Becca, since we had just met the year before and now were somewhat obsessed with each other.
So, to summarize, Break #1 (2002), spanning 5 months, at the age of 20-21, in Los Angeles, consisted of:
- Project #1 (major): Music Mint -> explored and lost interest
- Project #2 (minor): Wimpus -> Sachin pulled it off
- Personal project: Becca -> success!
My second break came in 2006, after finishing at Google. From November until August 2007, I had all my time to myself. I wrote with relish on this very blog, the most I have ever written before or since. I was enthralled by trying to figure out how to get Pandora running on my Treo, even though they didn't have a public API and I had never programmed Palm before (it was terrible). I was also excited about getting my voicemails as transcribed emails, and I played around with Sphinx for that. Finally, I was intruiged by web-apps, and made my very first one all on my own. I also applied for grad school in neuroscience. Most importantly, I went on a 1 month-long survival school, the best thing I have ever done in my life, then and since. I read a bunch of books, as the Book Notes entries on this blog attest.
So, to summarize, Break #2 (2006-2007), spanning 10 months, at the age of 25-26, in Walnut Creek, CA, consisted of:
- Project #1: Apply to grad school -> got into MIT and went!
- Project #2: Make a web-app -> released one!
- Project #3: Blogging -> did a lot of it
- Project #4: Pandora on Treo -> beyond my skills so didn't go anywhere
- Project #5: Voicemail to Text -> Powerbook died, which terminated my momentum
- Projects (minor): Read and watched lectures about quantum physics, artificial intelligence (hence the web-app), and computational neuroscience
- Personal project #1: Read nonfiction books -> completed
- Personal project #2: Survival school -> best experience of my life
My third break came in 2015, after I finished publishing two papers from my PhD work in neuroscience at MIT. I'm in Break #3 as I write! We left Boston in December and we've moved to Oakland, CA. It's been 3 months so far, and I anticipate it to continue for a total of 10 months, like break #2. Becca is pregnant, so we've been preparing our new house for the baby (and for ourselves as well). I've been assembling lots of furniture, putting up curtain rods and curtains, and shopping. I've also become somewhat obsessed with the economics of money, as it relates to Bitcoin and investing, specifically in new issue, but hopefully I'll write more about this in the future. Finally, I've beccome somewhat passionate about making photographs reproduce what the eye+brain sees. I have several ideas for how to help make this happen, and with the new Android Camera2 api, I think I have a platform for testing these ideas. So hopefully I'll make progress on that as well. But given my history, I probably won't succeed on all fronts.
So, to summarize, Break #3 (2015-2016), spanning 3 months so far, at the age of 34, in Oakland, CA, consists of:
- Project #1: Economics of money -> read 2 books so far, watching Coursera lectures, plan to write a few blog posts with my own, (hopefully) novel ideas
- Project #2: Computational photography -> want to make Android app to test some ideas for improving photo image quality
- Personal project: Baby is coming! -> want to observe a mind grow and develop, and want to give the child a better childhood than I had (mine was good, but I see areas for improvement). I will probably spend ~6 months with the baby after they are born, before going back to a specific job in neuroscience.
So, why was I motivated to write this smidgen of self-reflection?
I am often under the impression that I am changing. That my ideas are changing, that my outlook is changing, that what I think is worth spending time on is changing. But looking back now, from the age of 20 to 34, I see that very little has changed in this regard. Given unstructured time, I split my life into 2. On one side are my creative projects, which are motivated by both my desire to learn and understand and my desire to solve a problem in my life. These projects have clear deliverables, such as a blog post explaining a topic or an app that does something neat that no other app does. On the other side, always, there is a personal project, one that gives me the emotional foundation from which I draw the energy to pursue my creative projects. First it was Becca, then it was myself at survival school, and now it is the baby.
So it seems that as much as I like to believe that I've changed over the years, the data seem to argue otherwise... ]]>Comments: ]]>omar: that's a pretty remarkable conclusion based on this paucity of facts. might what you did at stanford, google and mit say something about whether you've changed or not? or are those just jobs, like F work man am i right?
also, i never knew about the vacuum cleaners. i must've missed that post. when i change the settings now, in chrome, and click the button, the vacuums don't start up. you might want to fix that, or mark the page deprecated.
glad to see you writing again
Nicky: so fun to read. Also, that baby is so lucky to have such an interesting and loving person as a father.
nikhil: see omar, even after all the years, you still read my blog!!! what more proof do you need that nothing has changed :)
sure, my interests have varied - stanford was all about learning how to code and do product design, google was executing with those skills, and mit was about learning neuroscience and trying to figure out a way to study the mechanism of consciousness. so the transition from consumer product design to neuroscience is vast, yet i still sit here, with my unstructured time, doing more or less the same thing.
omar, because you asked, i've fixed the vacuum cleaners to properly restart when you click the button, after the game has finished. that was actually an old bug that i just never fixed.
Neha: What books did you read about money? I'm also interested in money, since I've been learning about Bitcoin. Also, how did you decide on that Coursera class?
nikhil: Neha!
I finished reading "Money - An unauthorized biography" a few weeks ago, and am going at "The Empire of Value" right now. The second one is a translation from French, and it's much less clear than the first. I got a lot of good ideas out of the first book, and I'm planning to blog about both soon.
The Coursera class was recommended to me by a stranger who contacted me about C. elegans stuff. We chatted on the phone and realized we were also both interested in economics, and he had listened to those lectures and recommended it. I am on lecture 6 now - so far it is really a class less about money and more about banking, which is interesting in its own right. It's amazing how we are able to use so many things without needing to understand how any of them work.
The Real Nikhil: hi, I really want to have the username @nikhil on twitter, is it possible for you to change it so I can have your @? I will pay if necessary
nikhil: How much will you pay for the handle? I have gotten many other nikhils already asking for it too. ]]>
Write Comment]]>
Lifenikhil2016-02-11T10:52:08-08:00Some news about my worm research
http://nikhil.superfacts.org/archives/2015/09/some_news_about.html
I recently published my second first-author paper, rounding out the work of my time in grad school. MIT News wrote about it, and I was also interviewed by Lab Equipment about the research. Enjoy! ]]>
Write 1st Comment]]>
Sciencenikhil2015-09-23T19:57:07-08:00